
編輯導讀:雖然技術的進步,人臉識別在生活中的應用越來越普遍。在上篇人臉識別的基本原理中,作者介紹了人臉識別背後的原理和方法,本文順著這個思路繼續完善人臉識別的基本產品原型,希望對你有幫助。

一、產品原型
簡化的產品原型中包括識別前端和識別伺服器兩部分。
識別前端承擔人臉照片採集和識別結果反饋職責,是面向用戶交互的入口。目前主流的產品形態包括人臉考勤機、人證核驗終端和人臉識別閘機等。
人臉識別伺服器主要包括人臉底庫管理和識別演算法管理,並基於產品特點包含對應的業務模塊,如考勤報表、預警記錄等,實現基本的業務閉環。
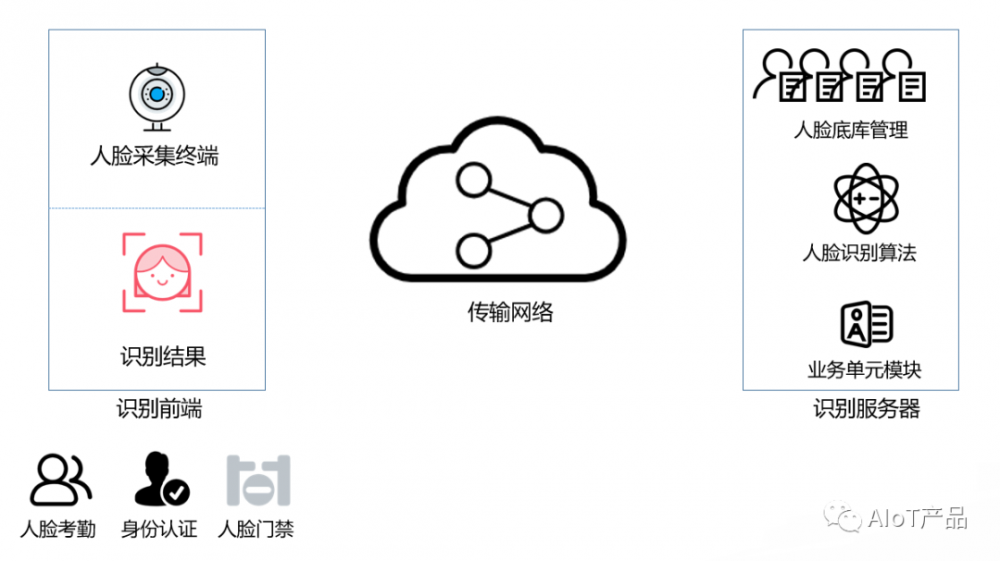
目前的產品原型,已有了基本框架,但系統需求和設計較簡單,無容錯能力,用戶體驗較差,離可用有較大的差距,需要繼續對需求深化和細化。
人臉識別在實際使用中可能出現以下情況:
- 採集到的人臉照片角度、大小等和預設的人臉底庫不一致,系統無法辨識;
- 採集的人臉照片和人臉底庫像素不一致,系統無法進行相似度計算;
- 環境、燈光等干擾造成成像質量較差,導致漏識別、誤識別;
- 比對速度較慢,精準度不夠,用戶使用抱怨多。
二、解決思路
在產品研發過程中,經常會出現這種產品實際體驗和預設體驗不一致的狀況。當發生這種情況時,需要認真分析原因,理順解決思路,不斷對產品迭代升級。
上面的問題其實可以分為兩類:
第一類是因為環境、距離、角度等因素干擾使得採集到的照片和系統底庫照片不一致,導致相似度計算有問題;
第二類問題是人臉相似度計算速度太慢、精度偏低。
其中第二種問題一般出現在演算法層面,需要協同演算法工程師進行演算法更新、升級進行解決。
我們將目標聚焦在第一類問題,即待識別照片和識別底庫不一致的情況。這種情況下,我們可以分別從採集照片和底庫照片兩個角度入手,提出針對性的解決思路:
思路一:限制通過前端採集到的照片,保持與人臉底庫的一致性。
比如,當強制採集照片和底庫都採用身份證照片時,系統比對通過率較高。類似的方法在較早的人臉考勤機中使用,通過限制用戶在打卡時的表情、距離、光線等提升精度,並強迫用戶通過同樣的前端採集並識別人臉,俗稱「同源識別」。
強迫用戶在人臉打卡時保持姿勢固定不動,用戶體驗很差。目前市面上主流的人臉識別系統均採用「動態識別技術」,不限制用戶保持靜止,在移動過程中即可完成識別過程,並且不要求採集照片和識別照片同源。
思路二:增加底庫中照片的數量,將人員不同角度、環境、距離的照片都錄入系統,提高比對的成功率。
這種做法操作難度很大,變數條件過多,基本無法實施。即使系統存儲了多張照片,問題沒有完全解決,識別精度並沒有明顯提升,且由於增大了數據量,增加了運算的複雜性,降低運算速度,系統響應時間也相應延長。
既然沒有辦法限制採集照片和底庫照片,在基本不影響精度和速度的前提下,可以在採集和比對之間插入中間環節,對照片進行處理,使得兩者儘可能相似。
在人臉識別和其他圖像處理領域這是種通用做法,並有專業名稱叫做「圖像預處理」。不管是在傳統的人臉識別系統還是基於深度學習的人臉識別系統中,都少不了這個環節。對原有的系統設計更新如下。
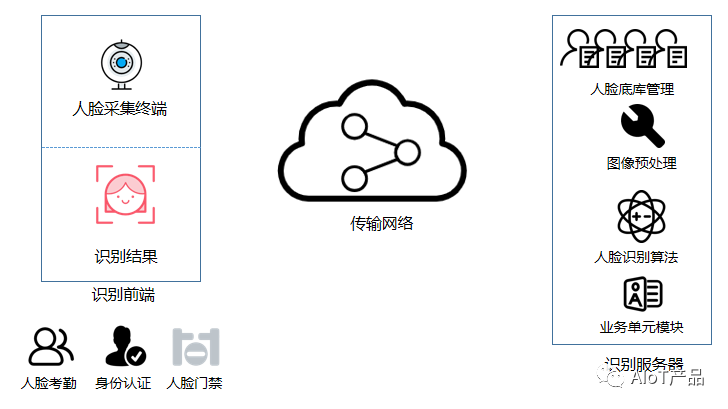
接下來對圖像預處理所包含的內容和需求做簡單的介紹。
1)設置ROI
當圖像內容包含過多像素時,系統很難定位到有效信息。比如,當圖像整體像素大小為800*800,包含人臉的區域像素只有200×200,其他均為背景,直接比對效果很差。可以對圖像進行預處理,快速找到包含有效信息的目標區域,即Region of Interest(ROI),「感興趣區域」。
在人臉識別系統中,可以對採集到的人臉照片,通過方框、圓、橢圓、不規則多邊形等方式勾勒出需要處理的區域,在這個區域內進行進一步處理或者直接對比。
尋找ROI有很多方法,比如基於膚色。從顏色上看,不同顏色人種的膚色在照片上具有穩定的特徵,不會隨表情、角度、尺寸等而發生變化。可以根據膚色屬性的這種特點和規律建模,快速識別到人臉ROI,從而將人臉區域和非人臉區域分開。
2)幾何變換
由於成像、採集角度等原因可能造成採集的人臉有一定的變形,對於肉眼來說這些變形並不會帶來太大的干擾,但對計算機來說卻是截然不同的。
這種情況叫做圖像的「幾何失真」,可以對圖像進行縮放、翻轉、仿射、映射等幾何變換最大程度地消除。幾何變換通常不改變圖像的像素值,而是將像素進行坐標變換,改變像素之間的排列關係,進而將注意力集中在圖像內容本身的特徵,而不是位置、角度、尺度等其他信息。
3)閾值處理
幾何變換由於不改變圖片的像素值,無法解決由於燈光等環境因素導致圖像呈現出不同情況。以灰度圖像為例,使用8bit表示某一像素時,單像素就存在256個灰度階,直接利用灰度階進行計算會帶來計算誤差。
這種情況下,需要對灰度階進行限制,盡量將採集圖像和底庫照片的灰度階統一,從肉眼上圖片可能會有些失真,但不影響計算機的處理和識別。可以根據實際情況,將256個灰度階劃分為幾個區間,將區間內的像素指定為某一個像素值,減少不同灰度值所帶來的影響,這種處理方法稱為「閾值處理」。
4)雜訊去除
圖像在形成、傳輸過程中往往會受到干擾,在結果圖像中引入雜訊。輕度的雜訊信號不會幹擾圖像的可觀測性,但當雜訊嚴重時,圖像中呈現出較多的無用信息,人臉無法識別或出現誤識別等情況。

在盡量保留圖像可觀測信息的情況下,檢測出現的雜訊並進行過濾,這個過程叫做「圖像濾波」。圖像濾波是圖像預處理中不可缺少的環節,一般通過構造圖像濾波器進行解決。濾波器可以高效地去除噪音,能夠保留圖像目標的特徵,並不會損壞圖像輪廓及邊緣。
對於圖片中經常出現的雜訊,通過統計學手段可以發現其特點,進而開發出通用濾波器,比如均值、中值、方框、雙邊等濾波進行噪音過濾。
當然,有一些雜訊使用成熟的濾波技術去除時效果較差,而必須自行設計濾波,這種方法也被稱為「卷積技術」。
不管是在傳統機器學習還是基於深度學習的人臉識別系統中,都採用了卷積技術,不同點在於值的填充方式。傳統系統由人工進行設計並填充,而深度學習可以通過自動學習得到所需要的值,處理起來更加靈活、高效。

5)其他處理
除了列舉到的常規預處理手段,人臉識別系統中還會用到其他預處理手段,比如顏色變換、圖像分割等。這些需求可以根據具體場景下圖像的特點和產品需求進行細化,實現圖像更精細化的處理。
除了進行圖像質量處理,在產品設計時也需要考慮性能指標。由於增加了預處理手段,可能會影響人臉識別速度,增大了系統響應時間,所以必須在精度和速度之間取得平衡。
很多時候,往往是由用戶需求驅動技術的進步。對於人臉識別系統來說也是如此,為了增強抗干擾能力而增加了圖像預處理階段,雖並不完美但保證了產品的落地,驅動技術尋找更優的方案,達到產品和技術的良性互動。
接下來,我們繼續從產品的角度對人臉識別進行拆解,並提出完善思路。
作者:AIoT產品,10年B端產品設計經驗;微信公眾號:AIoT產品